
分布式事务相关的总结
发表于|更新于
|浏览量:
分布式事务
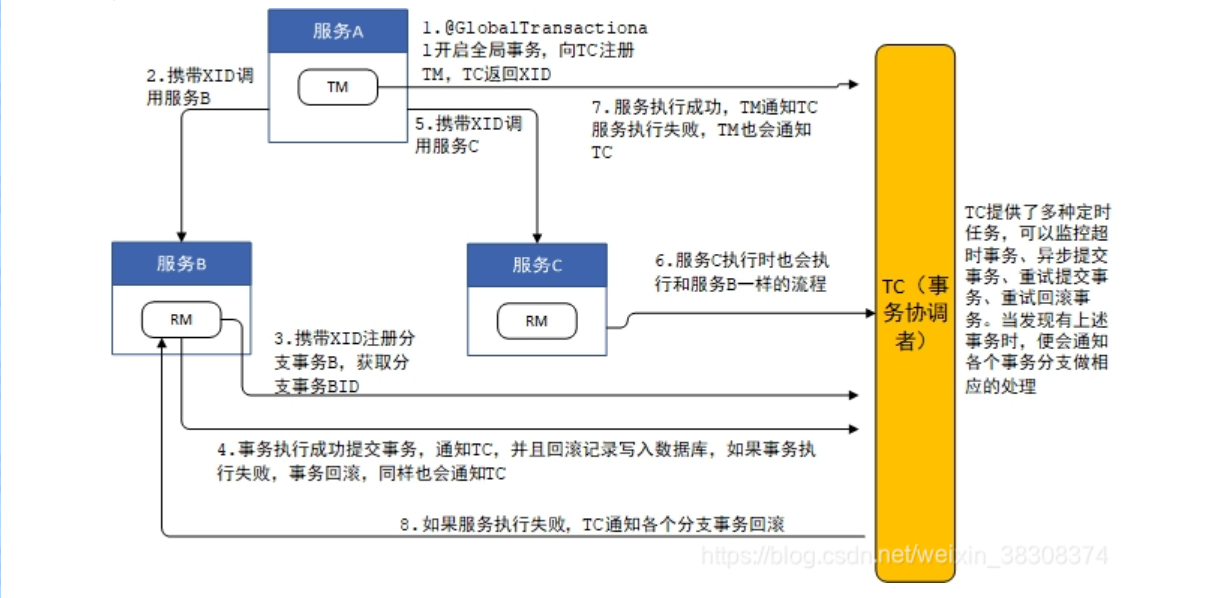
TC 如何知道哪些RM属于同一个全局事务?
以Seate框架为例,在TM向TC发送全局事务开始时,TC会生成对应的全局事务ID(XID),并发送给TM。TM 将 XID 放入当前线程的 ThreadLocal 中,后续的 RM (资源管理器) 分支事务通过解析该 XID 来注册分支。如果涉及RPC调用,每次调用时会在请求头部传递这个XID,让RM知道这个XID,RM向TC发送分支事务开始时,就会携带这个XID,从而告诉TC这个RM属于哪一个全局事务。
在多线程中,由于每个线程的XID是线程私有的,所以无法确定哪些RM属于同一个全局事务。这时全局事务会失效。解决方案可以是在开启新线程时,将XID传递给新线程,新线程的XID会继承父线程的XID。这样子线程的XID就会和父线程的XID一致,从而可以确定哪些RM属于同一个全局事务。
文章作者: 纳斯卡可
版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 纳斯卡可`Blog!
赞赏
 wechat
wechat

相关推荐
2026-01-31
AQS是什么?
【Java并发】AQS详解:JUC包背后的“幕后大佬”在 Java 并发编程(JUC)的世界里,我们经常使用 ReentrantLock、CountDownLatch、Semaphore 这些赫赫有名的工具类。 但你是否想过,这些功能各异的工具背后,其实共用着同一套“底盘”? 这就是我们今天要聊的主角——AQS (AbstractQueuedSynchronizer,抽象队列同步器)。它是 JUC 包的心脏,掌握了它,你就掌握了 Java 并发的半壁江山。 一、 什么是 AQS?AQS 是一个用于构建锁和同步器的框架。 如果把 ReentrantLock、CountDownLatch 等比作是成品的汽车(跑车、卡车、公交车),那么 AQS 就是通用的汽车底盘和引擎。 AQS 负责脏活累活:它处理了线程的排队、阻塞、唤醒、线程安全等最复杂的底层逻辑。 同步器负责业务逻辑:具体的工具类只需要告诉 AQS,“什么时候算获取锁成功”,“资源一共有多少”,剩下的交给 AQS 即可。 简单来说,AQS 是一个“原材料”,我们可以根据它加工出各种各样的同步器。 二、 AQS 的核心架构AQ...
2026-02-07
Java中的NIO就是操作系统的同步非阻塞IO吗?
Java NIO:不仅仅是“非阻塞”,更是 IO 模型的“Pro Max”在 Java 后端面试或高并发系统设计的讨论中,NIO (New I/O) 永远是一个绕不开的话题。 很多同学在初学时,往往会被教科书上的定义绕晕: “NIO 是同步非阻塞的。” “NIO 有三大组件:Channel、Buffer、Selector。” “NIO 性能比 BIO 好。” 但如果继续追问:“为什么非阻塞就快?Selector 到底是个什么东西?它和操作系统的 epoll 有什么关系?”很多人可能就卡壳了。 今天我们就从操作系统的底层模型出发,来聊聊 Java NIO 的前世今生,以及为什么我说它是 IO 模型的“Pro Max”版。 1. 痛点:BIO 时代的“贵族服务”在 JDK 1.4 之前,我们使用的是 BIO(Blocking I/O,阻塞 IO)。BIO 的编程模型非常简单符合直觉:建立连接 -> 读数据 -> 写数据。 但是它有一个致命的弱点:阻塞。就像一个传统的餐厅,每一桌客人(Socket 连接)必须配备一名专属服务员(Thread)。 客人看菜单(数据未就绪...
2026-02-07
Kafka为什么这么快
深度解析:为什么 Kafka 能快到“突破天际”?—— 论 Kafka 的机械共鸣设计在分布式系统领域,Apache Kafka 几乎是高性能消息队列的代名词。令人惊叹的是,作为一个基于磁盘存储的系统,Kafka 的吞吐量竟然能超越许多基于内存的数据库。 很多人将其归结为“快”,但这种快并不是某种单一的黑科技,而是一场对硬件特性的极致压榨。这种设计思想在计算机科学中被称为 “机械共鸣” —— 即了解底层硬件的工作原理,并让软件设计顺应这些原理。 本文将从五个核心维度,拆解 Kafka 性能神话背后的技术思考。 一、 颠覆认知:磁盘并不慢,随机读写才慢很多人对 Kafka 的第一个疑问是:“数据存磁盘上,怎么可能快?” 事实上,磁盘的顺序写(Sequential Writing)性能极高。在某些场景下,磁盘顺序写的速度甚至可以媲美随机内存读写。 Kafka 的做法:Kafka 将所有消息以 Append-only(仅追加) 的方式写入日志文件(Log)。它不执行任何随机位置的更新,也不删除单条数据。 技术思考:通过将“逻辑上的随机写”转换为“物理上的顺序写”,Kafka 绕过了...
2026-02-16
Kafka的多副本同步机制
深度解析 Kafka 多副本同步机制:从 HW 到 Leader Epoch在分布式系统中,数据的一致性和高可用性永远是核心课题。Kafka 作为顶级消息流平台,其高可靠性主要依赖于多副本(Replication)机制。本文将带你深入底层,剖析 Kafka 副本之间是如何协同工作、确保数据不丢不重的。 一、 核心角色与概念在深入同步流程之前,我们先统一几个关键术语: Leader 副本:每个分区(Partition)在创建时,由 Controller 负责指派 Leader。Controller 会从 AR(Assigned Replicas,所有副本) 列表中找到第一个在 ISR 中的副本作为优先 Leader。所有的读写请求都由 Leader 处理。 Follower 副本:不处理客户端请求,只负责从 Leader 拉取(Pull)数据。 ISR (In-Sync Replicas):与 Leader 保持同步的副本集合。判断标准是 replica.lag.time.max.ms(默认 30s),只要 Follower 在这个时间内向 Leader 发起过同步请求且进度没...
2026-03-06
Raft算法的两种成变更员
Raft 算法揭秘:如何安全地进行集群成员变更?在分布式系统的生命周期中,集群成员变更(Membership Change)是一个不可避免的操作。无论是为了扩容以应对突发的流量洪峰,还是为了替换发生硬件故障的死节点,我们都需要在不停机、保证强一致性的前提下,将集群从“旧配置”平滑切换到“新配置”。 然而,这在分布式环境中绝非易事。本文将深入探讨 Raft 算法中成员变更面临的“脑裂”挑战,并详细拆解两种主流的解决方案:联合共识(Joint Consensus) 与 单步变更(Single-Server Change)。 一、 核心痛点:为什么成员变更这么难?假设我们有一个由 A、B、C 三个节点组成的集群(旧配置 $C{old}$),多数派为 2。现在我们需要扩容,加入节点 D、E,使得集群变成 5 个节点(新配置 $C{new}$),多数派为 3。 最朴素的想法是:管理员直接向所有节点发送一个切换到 $C_{new}$ 的命令。 灾难瞬间发生——“脑裂(Split-Brain)”:由于网络延迟的不确定性和各个节点处理速度的不同,这 5 个节点不可能在同一绝对时间点切换配置。 ...
2026-02-26
kafka为什么会重复消费
深入理解 Kafka:Offset 提交、重试机制与重复消费的“罗生门”在分布式系统的面试和生产实践中,Kafka 的“重复消费”是一个绕不开的话题。很多开发者会有这样的疑惑:“我明明配置了自动提交,代码里也写了 try-catch,为什么数据库里还是会有重复数据?” 要彻底解决这个问题,我们不能只看表象,必须深入 Kafka 的 Offset 提交机制 和 重试策略,理解为什么 Kafka 只能保证 “At Least Once”(至少一次),而不能天然保证 “Exactly Once”(恰好一次)。 一、 Offset 的双重人格:内存 vs 磁盘在 Kafka 消费者(Consumer)端,Offset(位移) 其实有两个完全不同的概念,理解它们的区别是破解重复消费的第一步。 1. Current Offset(当前读取位置) 存在哪里? 消费者的内存中。 代表什么? “我现在读到哪一行了”。 怎么变? 只要消费者调用 poll() 拉取到了新消息,这个指针就会自动往后移。哪怕你没有任何提交操作,只要进程不挂,消费者就能一直顺畅地往下读。 2. Committed Off...
评论