
关于爬取贴吧的两种网页差异
百度贴吧爬取时两种网页结构的差异
百度贴吧作为国内极具影响力的中文社区,其海量的用户生成内容(UGC)是进行市场调研、情感分析、热点追踪的宝贵数据资源。但在实际爬取过程中,很多开发者会遇到“明明XPath规则正确却爬不到数据”的问题,其核心原因在于百度贴吧存在两种差异化的前端渲染结构。
一、前置知识
1.1 贴吧URL结构分析
贴吧的帖子URL遵循固定格式,掌握后可批量构造爬取链接:
单页帖子URL:
https://tieba.baidu.com/p/[帖子ID](默认显示第一页)分页帖子URL:
https://tieba.baidu.com/p/[帖子ID]?pn=[页码](pn参数指定页码,如pn=2表示第二页)
例如:帖子https://tieba.baidu.com/p/789012345?pn=3表示ID为789012345的帖子的第三页内容。
二、两种网页结构的深度对比
通过Chrome开发者工具(F12)查看网页源码,我们发现两种结构的核心差异集中在帖子内容容器和发布时间节点,以下是具体对比:
2.1 结构一:传统版(无clearfix后缀)
通过“检查”功能定位到帖子内容和发布时间节点,其HTML结构如下:

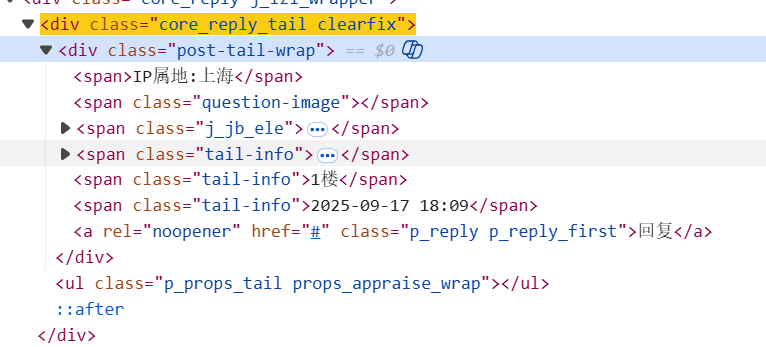
对应的XPath解析规则:
回复内容:
content_list = html.xpath('//cc/div[@class="d_post_content j_d_post_content "]')
之后再循环获取评论内容:content_list = [''.join(i.xpath('.//text()')) for i in content_list]发布时间:
create_time = html.xpath('//div/div[@class="core_reply_tail clearfix"]')
之后再循环获取里面的时间:create_time = [i.xpath('.//span[@class="tail-info"]/text()')[-1] for i in create_time](取最后一个tail-info的文本)
2.2 结构二:新版(含clearfix后缀)
其HTML结构调整了class属性和节点层级:

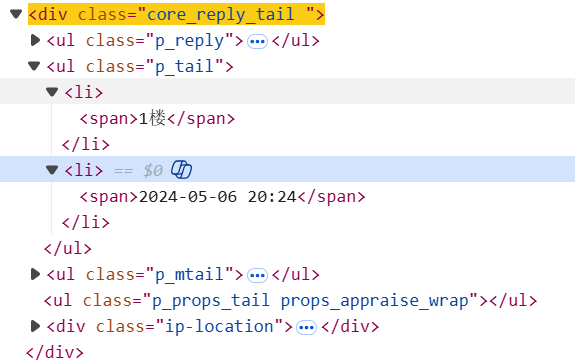
对应的XPath解析规则:
回复内容:
content_list = html.xpath('//cc/div[@class="d_post_content j_d_post_content clearfix"]')
之后再循环获取评论内容:content_list = [''.join(i.xpath('.//text()')) for i in content_list](注意两个空格)发布时间:
create_time = html.xpath('//div/div[@class="core_reply_tail "]')(
之后再循环获取里面的时间:create_time = [i.xpath('.//ul[@class="p_tail"]/li[last()]/span/text()')[-1] for i in create_time]取p_tail最后一个li的span文本)
关键提醒:XPath中class属性的匹配是精确匹配,空格和后缀的差异会导致解析失败。在编写规则时,必须完全复制网页源码中的class值。
三、示例代码
示例代码如下:
1 | # 提取帖子评论数据第一种 |
四、关于爬取贴吧列表
1.问题分析
贴吧列表页面如下所示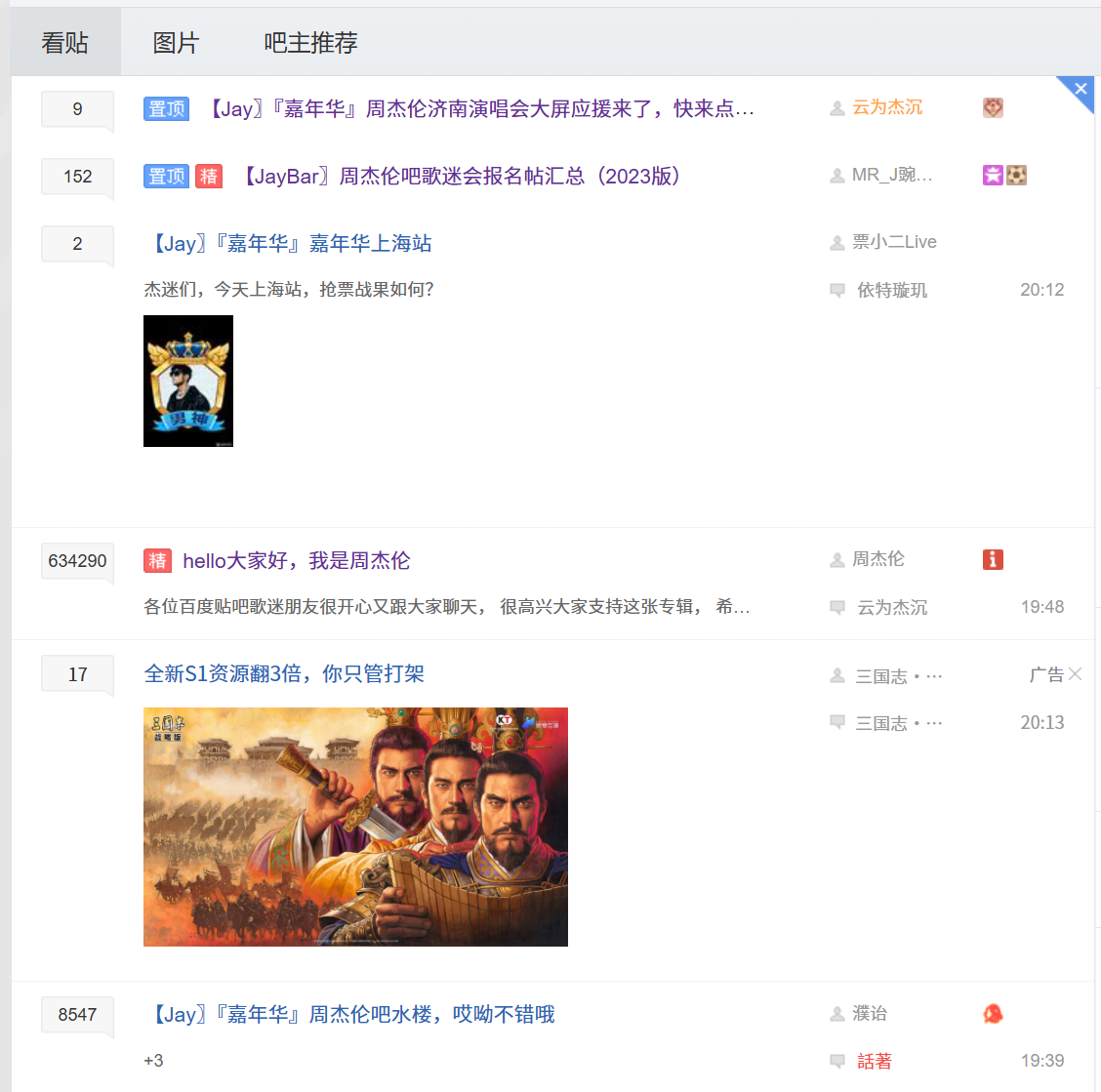
现在我们想要获取列表页的贴子名称,帖子作者,帖子链接,帖子时间
原来的代码如下:
1 | # 提取标题、链接、发帖人和时间 |
看上去似乎没有什么问题 ,但是运行代码的时候,发现爬取的帖子有些标题跟时间对不上这会导致一些问题。
所以这到底是为什么呢?
我们可以打开f12查看网页源代码,查看列表页面的html结构,通过观察可以发现,一些帖子的标题,链接,发帖人的html结构跟大部分还不一样。
例如普通的标题页面结构如下:

但是某些帖子标题的html结构如下:

可以发现少部分贴子的标题比普通的多了member_thread_title_frs 这一段文字 导致获取不到一些帖子标题,所以也就造成了之后的时间不一致的问题。
2.解决方法
解决方法很简单只需要在多匹配那少部分的内容即可。
可以把原来的正则表达式替换为//div[contains(@class,"threadlist_title") and contains(@class,"j_th_tit")]/a[1]/@title。
这样就能匹配只要有threadlist_title pull_left j_th_tit 的内容了。
但是注意这里的作者名称,一个帖子会有两个作者名称。第一个是帖子作者,第二个是最后评论的人的名称。这里我们只需要获取第一个作者名称即可。
于是关于作者名称的正则表达式用or即可。
修改的完整代码如下:
1 | # 提取标题、链接、发帖人和时间 |
这样修改之后就可以匹配到正确的完整的数据了。
 wechat
wechat

